 The Health checker is a background continuous task that monitors different aspects of the Flexxible|SUITE the state of health of the platform's components. This task runs in every running WorkerStructure service instance.
The Health checker is a background continuous task that monitors different aspects of the Flexxible|SUITE the state of health of the platform's components. This task runs in every running WorkerStructure service instance.
The Health checker can detect many health problems and automatically correct some of them. Both problems detected and automatic fixes applied are notified by email to the recipients indicated by the setting "HA_AlertRecipientTo". Please, set up this setting to ensure that someone is notified when something on the platform goes wrong.
Additionally, notifications will be emitted as SNMP traps to the list of SNMP listeners specified by the "HealthCheckerSNMP" setting, which contains a semi-colon separated list of SNMP listener FQDN or IPs and port numbers (the default port when not specified is 162).
To prevent bloat, every different notification is sent only once per instance of the WorkerStructure service in a period of time -usually one hour, but depends on the kind of notification- until the error condition stops being detected.
The following checks are performed:
Database connectivity
Every 30 seconds, an innocuous SQL command is sent to the Flexxible|SUITE database and a notification that the SQL Server access connectivity has been lost is sent when the command can't be performed.
This notification will be repeated every hour while there is no connectivity.
When the Health checker detects that the SQL command can be executed successfully again, it will notify that the database connectivity has been restored.
When database connectivity is lost, many of the other checks are suspended until database connectivity is restored, since the other tests require it.
Databases synchronization
Every 5 minutes, the Flexxible|SUITE database is checked for replication consistency if they are set up for high availability (whether by mirroring or by belonging to an availability group with AlwaysOn).
A notification is sent if the database is not synchronized in both nodes or an error occurs while trying to perform the check.
VM Managers
Every 5 minutes, a check is made on every VM Manager defined in the VM Managers list in the Flexxible|SUITE web console. The check consists of checking the reported status of every node in the VM Manager.
A notification is emitted for nodes presenting an abnormal status or if an error occurs while trying to perform the check.
Broker farms
Every 5 minutes, a check is made in every broker farm defined in the Broker Farms list in the Flexxible|SUITE web console.
Every XenDesktop delivery controller on the site is checked and a notification is sent for abnormal status or failure while checking.
Every hosting unit is tested for every XenDesktop site by retrieving information about one of the VMs in that hosting unit.
Additionally, the hosting connection between XenDesktop and the hypervisor is tested by obtaining hypervisor configuration data for the VM.
If Citrix License Server status checking is enabled (indicated by the setting "CheckCitrixLicenseServerStatus" = true) it is tested for accessibility and a notification is emitted if it is found inaccessible.
A notification is also sent for every fix applied.
VDI Appliances
Every minute, the VDI Appliances are checked.
If an appliance doesn't respond to ping on either the configured management IP address or the VMs IP address, it is considered to be down:
- The XenDesktop site is notified that sessions in the appliance are closed.
- The appliance down condition is notified
When the appliance begins to respond again to ping:
- The VMs (desktops and application servers) hosted in the appliance that had ongoing sessions are restarted.
- A notification that the appliance is up again is sent
If only one of the management IPs or the VMs IP doesn't respond to ping, it is notified.
If the appliance is up but the VDI Client service is not installed (or the appliance is not a Windows machine), information about CPU, RAM, and disk usage is collected.
Component instances
Every 24 hours, the active instance of the Flexxible|SUITE WorkerStructure service performs a check of the SUITE components and de-registers components no longer present in an infrastructure VM. For example, an instance of one of the SUITE services could have been moved from a worker VM to another one. This check ensures that the placing of every component is known so the "VCC Roles overview" in the Flexxible|SUITE menu can offer accurate diagnostics.
Health summary
Every 5 minutes, a general health check is performed against the main infrastructure components of Flexxible|SUITE to detect configuration or execution problems. These problems can include among others:
- incorrect application of some Group Policies needed for SUITE components to contact with message queue servers or database servers
- different binaries between different instances of the same component on different machines
A notification is sent whenever one of these problems is detected, with links to extend information about every issue.
Message queue status
Every 5 minutes the message queue is checked. The message queue allows communication and orchestrates activity between the different Flexxible|SUITE components.
A notification is sent if it is detected that over 50% of the total queue capacity is occupied by messages not being processed at a good rate. Such accumulation could happen if, for example, one of the SUITE infrastructure services got stuck or was accidentally disabled by an administrator.
To give time to administrators to diagnose and correct the problem before the queue gets eventually collapsed, the messages of the most accumulated message type are discarded.
Unregistered VMs
Every 5 minutes the active instance of the Flexxible|SUITE WorkerStructure service performs a check searching for unregistered VMs in the Broker Farms.
Users won't be able to connect to desktops or published applications that are unregistered.
If the setting "FixUnregisteredVMsRemotely" is set to "true", and the number of unregistered VMs is less than 20, a job to fix the unregistered status of each VM will be enqueued. This fix will be performed by the VDI Client service running on the unregistered VM and will try to correct the Windows Performance Counters and restart the Citrix Desktop Service to make the VM register.
Additionally, if more than 5 VMs are found unregistered, the list of unregistered VMs (whether desktops or application servers) will be notified, as it could mean a networking issue that could affect a big number of users.
NOTE: a check could take more time than its normal frequency. For example, checking the VM Managers could take more than 5 minutes. The frequency indicates how many minutes after the completion of the previous check is launched the next check.
SNMP Traps
From the 4.8 version, the health checker can notify through SNMP traps.
The subject keeps the following pattern:
{"SMTP_Subject_tag" setting value}: {Alert definition severity} - {Alert definition name} [ - {Additional info: element name (appliance, hosting unit, VM, etc)}]
E.g. INT: Warning - High RAM usage-Desktop - A00-01-002-0003
Codes
| Code | SNMP Trap Oid | Email notification subjects |
|---|---|---|
| HC_highQueueUsage | .1.3.6.1.4.1.59 | The VDIManager queue usage is too high ({0}%) |
| HC_SQLServerAccessRestored | .1.3.6.1.4.1.60 | Database access restored from {0} |
| HC_DBUnsynced | .1.3.6.1.4.1.61 | Flexxible|SUITE database unsynced or unhealthy |
| HC_VMManagerCheckFailed | .1.3.6.1.4.1.62 | VMManager health check failed from {0} |
| HC_DesktopManagerCheckFailed | .1.3.6.1.4.1.63 | Desktop broker health check failed from {0} License server failover for desktop broker '{0}' License server restored for desktop broker '{0}' |
| HC_ComponentInstanceCheckFailed | .1.3.6.1.4.1.64 | Check component instances failed from {0} |
| HC_HealthSummaryErrors | .1.3.6.1.4.1.65 | Global health summary reported problems from {0} |
| HC_ApplianceDown | .1.3.6.1.4.1.66 | Appliance {0} is down, detected from {1} |
| HC_UnregisterdVMs | .1.3.6.1.4.1.67 | [{lLevel}]: {lVMs.Count} were unregistered for the last 5 minutes |
| HC_SQLServerAccessLost | .1.3.6.1.4.1.68 | Database access lost from {0} |
| HC_DBSyncCheckError | .1.3.6.1.4.1.69 | Flexxible|SUITE database database sync status check failed from {0} |
| HC_VMManagerUnhealthyHosts | .1.3.6.1.4.1.70 | {lVMManager.Name} unhealthy host(s) |
| HC_DesktopManagerUnhealthyNodes | .1.3.6.1.4.1.71 | Desktop broker unhealthy nodes |
| HC_HUVMsListFailed | .1.3.6.1.4.1.72 | Failed to get VMs for hosting unit '{0}' from {1} |
| HC_HUHypConFailed | .1.3.6.1.4.1.73 | Hypervisor connection for hosting unit '{0}' failed from {1} |
| HC_DesktopManagerLicenseServerStatus | .1.3.6.1.4.1.74 | License server fail for desktop broker '{0}' |
| HC_DesktopManagerLicenseServerCheckFailed | .1.3.6.1.4.1.75 | Failed to check license status for desktop broker '{0}' from {1} |
| HC_ComponentInstanceRemoved | .1.3.6.1.4.1.76 | Missing component instance '{lInstance.DisplayName}' removed |
| HC_HealthSummaryCheckFailed | .1.3.6.1.4.1.77 | CheckHealthSummary execution failed in {System.Environment.MachineName} |
| HC_ApplianceUp | .1.3.6.1.4.1.78 | Appliance {0} is up, detected from {1} |
| HC_ApplianceManagementIPDown | .1.3.6.1.4.1.79 | Management network down for appliance {0} from {1} |
| HC_ApplianceVMsIPDown | .1.3.6.1.4.1.80 | VMs network down for appliance {0} from {1} |
| HC_ApplianceCheckFailed | .1.3.6.1.4.1.81 | Check appliance failed from {0} |
| HC_UnregisterdVMsCheckFailed | .1.3.6.1.4.1.82 | CheckUnregisteredVMs failed from {System.Environment.MachineName} |
| HC_highQueueUsageCheckFailed | .1.3.6.1.4.1.83 | Database access lost from {0} |
*Values in {braces} represent variables
Health checker monitoring
From the 4.11 version, Flexxible|SUITE contains a new section in Monitoring & Reporting to make easy the health checker tasks.
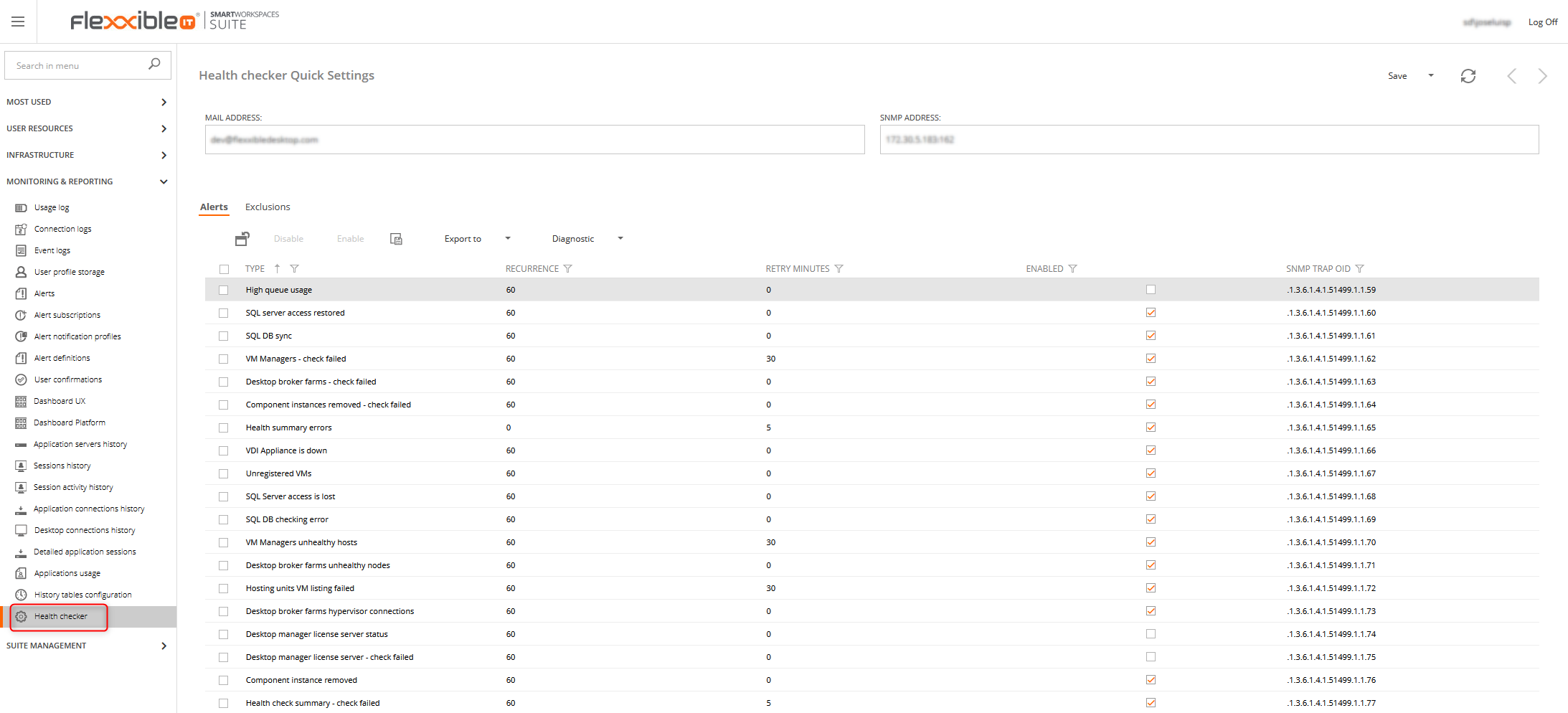 From this view, you can set up the health checker mail and SNMP addresses.
From this view, you can set up the health checker mail and SNMP addresses.
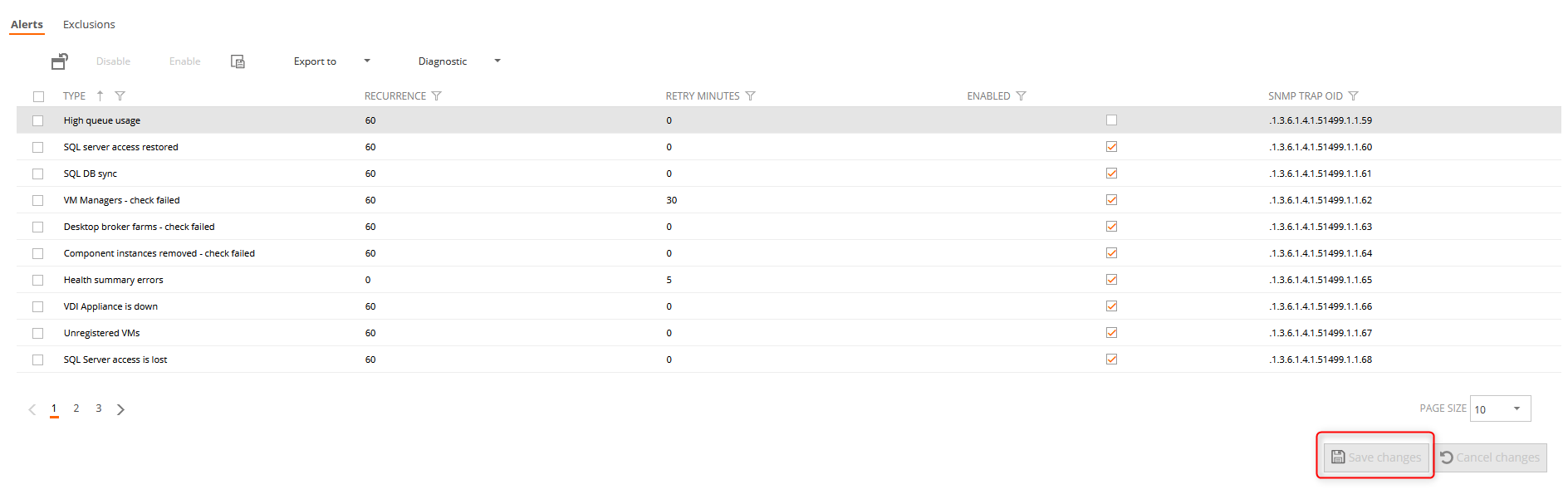
Alerts
In this tab, we can configure the SNMP traps, to enable and disable the alert, and indicate how often they are resent or not resent (recurrence = 0). To apply changes, you must click on the save changes button and finally on the main Save button.
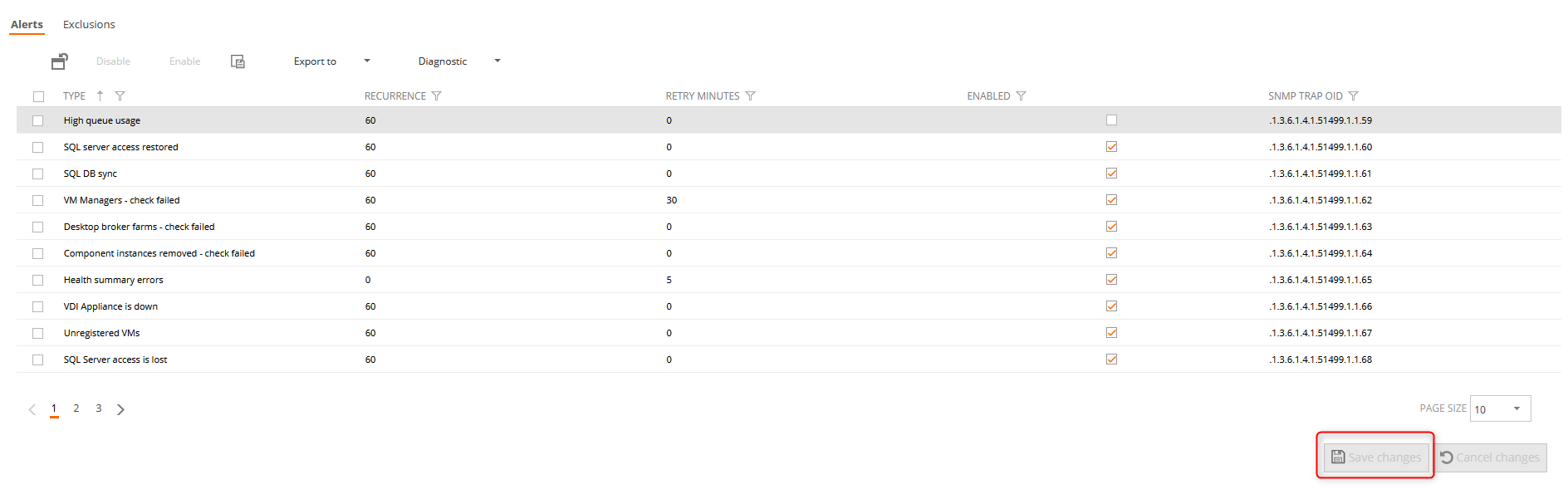 Retry minutes
Retry minutes
The "Retry minutes" column lets you specify a period of time within which an alert can be activated, but is not notified unless it is active through that number of minutes. This is intended to reduce alert notification spamming for intermittent issues that might happen due to transitory conditions.
A value of zero (default) means that the alert will be notified as soon as it becomes active. The maximum value for "Retry minutes" is 60 minutes.
Within the retry minutes period, the alert is evaluated with the normal cadency, which is arround 5 minutes for most of the alerts. If you specifiy a number of minutes smaller than this evaluation frequency, the alert might be notified later than the retry period. For example, if you used a 2 minutes retry time for the "Health summary errors" alert, which is evaluated every 5 minutes, the alert would be notified 5 minutes after its activation, because the retry minutes interval is checked when the alert is evaluated.
When the alert has a recurrence time and retry minutes, the notification will occur using the bigger of both values:
- with a recurrence time of 60 minutes and retry minutes = 5, it would be notified 60 minutes after its initial activation, and then every 60 minutes while the alert is active.
- with a recurrence time of 1 minute and retry minutes = 5, it would be notified 5 minutes after its initial activation, and then every 5 minutes while the alert is active.
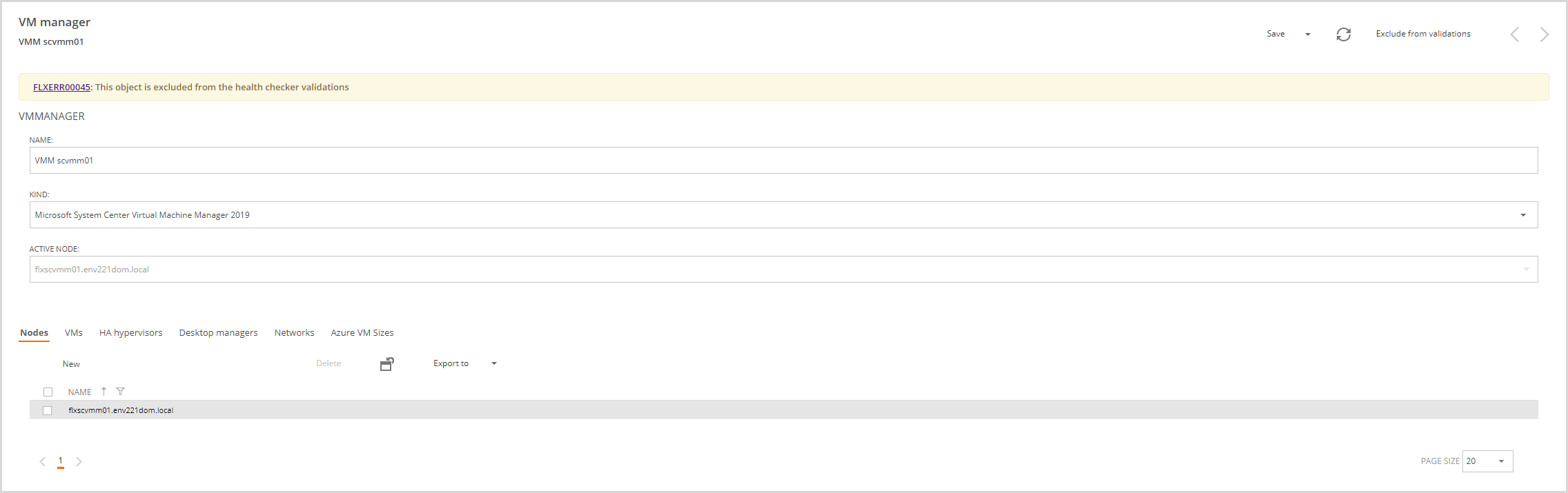
Exclusions
This feature applies to administrator roles.
We will also have a list of elements excluded from the validations, in this list, we will be able to eliminate exclusions and modify the date on which the exclusion ends.

Clicking on the exclusion you can modify or delete it.

A new drop-down button will appear called "Add health checker exclusion" that will allow us to add an exclusion.
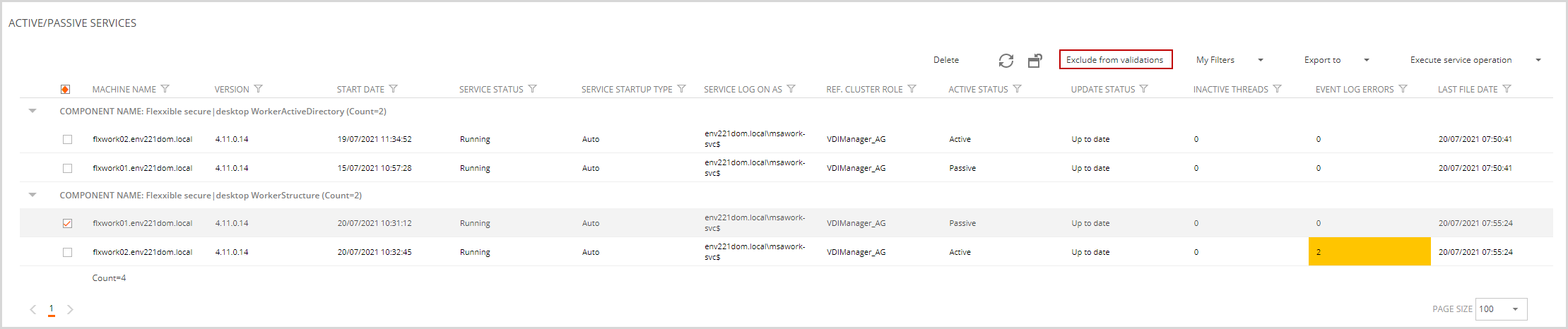

You can exclude the following elements:
- From VCC Roles Overview:
- Services
- Web console
- VCC Roles
- Desktop Broker Farms
- Appliances
- Desktop Broker Farms
- Hosting Units
- VM Managers
- VCC Roles
If the element is excluded, a warning will appear at the top of the detail with the following message "This element is excluded from Health checker validations".